Privacy Canada is community-supported. We may earn a commission when make a purchase through one of our links. Learn more.
Hash Collision Attack

A Hash Collision Attack is an attempt to find two input strings of a hash function that produce the same hash result. Because hash functions have infinite input length and a predefined output length, there is inevitably going to be the possibility of two different inputs that produce the same output hash. If two separate inputs produce the same hash output, it is called a collision. This collision can then be exploited by any application that compares two hashes together – such as password hashes, file integrity checks, etc.
The odds of a collision are of course very low, especially so for functions with very large output sizes. However as available computational power increases, the ability to brute force hash collisions becomes more and more feasible.
For example, let’s say we have a hypothetical hash function. A collision attack would first start with a starting input value, and hash it.

Now the attacker needs to find a collision – a different input that generates the same hash as the previous input. This would generally be done through a brute-force method (trying all possible combinations) until one was found. Let’s say we found a collision for this input in our hypothetical hash function.

The attacker now knows two inputs with the same resulting hash.
Practically speaking, there are several ways a hash collision could be exploited. if the attacker was offering a file download and showed the hash to prove the file’s integrity, he could switch out the file download for a different file that had the same hash, and the person downloading it would be unable to know the difference. The file would appear valid as it has the same hash as the supposed real file.
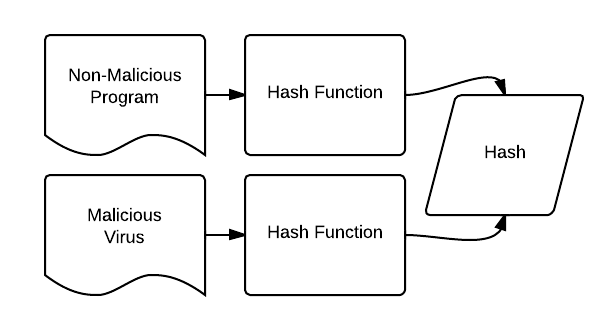
So – are hash collisions something to worry about? It depends on the hash function. MD5 and even SHA-1 have been shown to not be completely collision-resistant – however stronger functions such as SHA-256 seem to be safe for the foreseeable future. To learn more about digital security please see our list of the best VPN services in Canada, or Meilleur VPN, if you prefer French.