
Privacy Canada is community-supported. We may earn a commission when make a purchase through one of our links. Learn more.
What Are Hash Functions
A hash function is simply a function that takes in input value, and from that input creates an output value deterministic of the input value. For any x input value, you will always receive the same y output value whenever the hash function is run. In this way, every input has a determined output.
A function is basically something that takes an input and from that input derives an output.
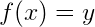
A hash function is therefore something that takes an input (which can be any data – numbers, files, etc) and outputs a hash. A hash is usually displayed as a hexadecimal number.
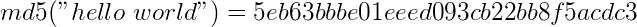
This is the hash function MD5, which from any input data creates a 32 character hexadecimal output. Hash functions are generally irreversible (one-way), which means you can’t figure out the input if you only know the output – unless you try every possible input (which is called a brute-force attack).
Hash functions are often used for proving that something is the same as something else, without revealing the information beforehand. Here’s an example.
Let’s say Alice is bragging to Bob that she knows the answer to the challenge question in their Math class. Bob wants her to prove that she knows the answer, without her telling him what it is. So, Alice hashes her answer (let’s say the answer was 42) to produce this hash:
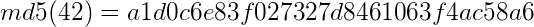
Alice gives this hash to Bob. Bob can not find out what the answer is from this hash – but when he finds the answer himself, he can hash his answer and if he gets the same result, then he knows that Alice did indeed have the answer. Hashes are often used in this context of verifying information without revealing it to the party that is verifying. To learn more about digital security please see our list of best VPNs in Canada.



