
Privacy Canada is community-supported. We may earn a commission when make a purchase through one of our links. Learn more.
Why Are Hashes Irreversible?
A common question many people have upon learning about one-way cryptographic hash functions is how the “one-way” part works. A certain amount of data goes through a process and a result is given – shouldn’t it be possible to do that same process in reverse, since we know what the process is in the first place?
Well there’s a very good reason – and it applies mostly the same to all hash functions, even though they are all implemented differently. Hash functions essentially discard information in a very deterministic way – using the modulo operator. For a quick review, modulus is essentially the same as saying “the remainder of” (applying to division). A quick example would be:
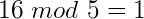
What’s happening here is that we’re dividing 16 by 5, and the result of the operation is whatever is left over – or the remainder.
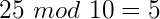
Obviously if the number was evenly divisible my the modulo then it would result in zero, and if it was less than the number it would remain as the number itself. Now – back to the important part. Why is this so important in one-way hash functions? Because the modulo operation is not reversible. If the result of the modulo operation is 4 – that’s great, you know the result, but there are infinite possible number combinations that you could use to get that 4.
Another thing to consider is that a lot of data is discarded during the hash process. While the input string may be as big as it wants, the output must always be of a set size determined by the function. Because of this, a lot of data is thrown out. It would be impossible to figure out the original data of the function with just the resulting hash – as not much of that data is left – the only workable method is to brute force every possible combination. If we could reverse a hash, we would be able to compress data of any size into a mere few bytes of data.



