
Privacy Canada is community-supported. We may earn a commission when make a purchase through one of our links. Learn more.
Guide to Cryptography Mathematics
Cryptography is the science of using mathematics to hide data behind encryption. It involves storing secret information with a key that people must have in order to access the raw data. Without cracking the cipher, it’s impossible to know what the original is.
While cryptography is also used in the science of securing data, cryptanalysis is also important to understanding the mathematics side of encrypting and decrypting data.
With cryptanalysis, the combination of mathematical tools, pattern finding, analytical reasoning, determination, and a bit of change. Cryptanalysts typically is a term used refer to those who attack systems, looking for weaknesses.
There are a few ways to apply cryptography to your files, and it mainly comes down to a difference of preventing your kid brother from reading your diary to blocking the government dead in its tracks from seeing your data.
The strength of cryptography depends on the resources and time it would take to recover the raw plaintext. However, the main result of cryptography should always be the same:
Ciphertext is very hard to figure out without knowing the proper decoding tool or key. With today’s advancement of computer technology, then it is a billion times more complicated than it used to be.
Even against a hacker who is extremely skilled, strong ciphertext would prevent the cryptanalyst from ever getting to the data.
This guide explores every part of the mathematics behind cryptography and different methods used to encrypt data with the latest algorithms.
History of Cryptography Mathematics
Even though modern cryptography mathematics is much different than in the old days, it’s still based on the same concepts used in ancient times.
The earliest known instances of cryptography were found in the hieroglyphics carved into a tone from the Old Kingdom of Egypt, dating back to 1900 BCE. While historians do not believe that the message was intended to be complicated, it was still meant to be intriguing and amusing to solve instead.
There are also clay tablets from Mesopotamia, even going back as far as 1500 BCE, that were to have encryption to hide a recipe for pottery glaze, since it was likely for commercial value and private to the seller.
Perhaps the most famous ancient source of cryptography is the use of monoalphabetic substitution cipher around 400 BCE in India, when Mlecchita vikalpa was explained as the “art of writing in cypher” was documented for the Kama Sutra, which was known as the communication for lovers.
Cryptography has advanced considerably in the past 100 years. You have likely seen simple cryptography, such as the Caesar cipher, also known as the shift cipher. ROT13 is one of the most common types of shift ciphers, which means that the alphabet rotates “13” times. See this figure below:
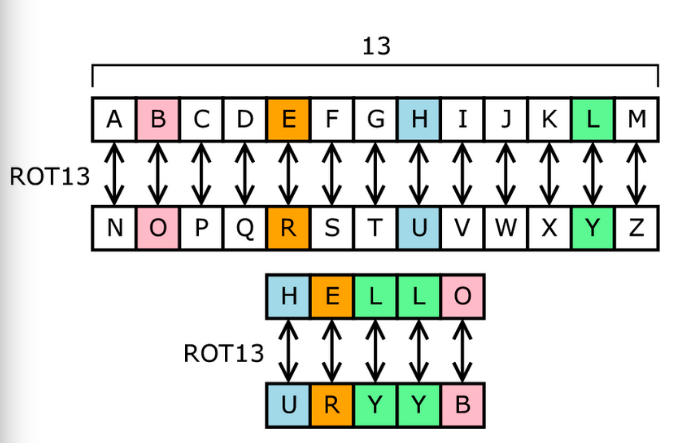
However, this is not the type of mathematical cryptography that can protect data in today’s world. The latest technology is used mostly to protect personal and sensitive financial information so that it is safely transmitted online, but all kinds of data has to be safely stored and kept private from those who wish to sell or otherwise use it fraudulently. Keeping this data safe falls under cybersecurity.
Understanding Cryptography Mathematics
Cryptography Mathematics – This refers to the use of mathematical techniques to encode plain text with hash functions and perform crypto-analysis to identify the original text from encrypted keys.
Terms of Mathematical Cryptography
There are some important terms that are necessary to understanding how cryptography mathematics work and what role algorithms play in modern cryptography.
Security Services
These break down into:
- Confidentiality: Information must not be available to unauthorized parties.
- Data Integrity: The data must be preserved throughout the encryption.
- Authentication: There are two ways to authenticate: source or integrity. With source authentication, the algorithm must assure the identity of the party that is generating or creating the information.
- Non-Repudiation: No one can deny a transaction, which is used mostly for email messages and digital signatures.
In cybersecurity practices, cryptography mostly refers to the encryption of sensitive data. Security systems are designed to make data the most confidential, but systems must also ensure complete integrity of the raw data. IT also must be available when needed, such as users logging into to see their data online.
Finally, non-repudiation methods are used to ensure that if someone sends information to another party, it’s easy to see who the original sender was. In this way, information about accessing the data is shared between the system and administrators.
Why Guidance is Needed for Cryptographic Algorithms
Cryptographic methods make it possible to set up security services as applications and protocols. These are necessary for protecting data security. In today’s digital world, there are a ton of open-source and proprietary data security algorithms available on GitHub. The community has made significant strides in data security algorithms, which is mostly thanks to the complex mathetics involved with each algorithm.
Since algorithms update all the time, there are always new data security threats that must be updated as well. This is why cryptanalysts often study the latest algorithms available, making it a double-edged sword to have open-source data security platforms.
The Importance of Keys in Crypto Algorithms
In cryptography, keys are the same as a pin, password, or pattern. It works just like a physical key would with any security locker or door. If an attacker can find out this key, then you likely did not have the latest algorithms protecting your system, or they were able to quickly crack the key, indicating an inferior cipher.
It’s also important that system managers take note of keys and how they are saved. Even with state-of-the-art technology, attackers often get into security lockers simply by understanding how the keys are used and saved after spending time inside of your system. As you can see, the management of keys is just as important as they were created.
Learn Classes of Cryptographic Algorithms
The mathematics of an algorithm change depending on the category of the algorithm. With digital cryptography, it’s easier than ever to create an algorithm, however not all are as strong as others. Within these algorithm categories, there are even further detailed methods with their own unique mathematical inputs.
The classes include:
- Asymmetric Encryption
- Symmetric Encryption
- Hash Functions
We describe these cryptography schools of thought below.
What is Symmetric Encryption
The primary functions of a symmetric encryption algorithm include:
- Achieve confidentiality through encryption and decryption, which is performed using just a single key
- Authenticates integrity and sources by using Message Authentication Codes (MAC), which is automatically generated and validated by the same key
- Generates pseudo random numbers
Before getting ahead of ourselves, we should discuss how we look at encryption for mathematical cryptography. In addition, encryption and decryption go hand in hand. They are usually meant to describe making a message completely unintelligible to all those without authorized access. If you can decrypt a message, you are a highly skilled cryptanalyst, or it could just be that your encryption was not that strong.
In order to appropriately and securely use encryption to protect data, we need a key made up of ciphertext.
With symmetric encryption, the same key is used to encrypt and decrypt the message. In modern cryptography, that may look like this string of Ruby and OpenSSL code:
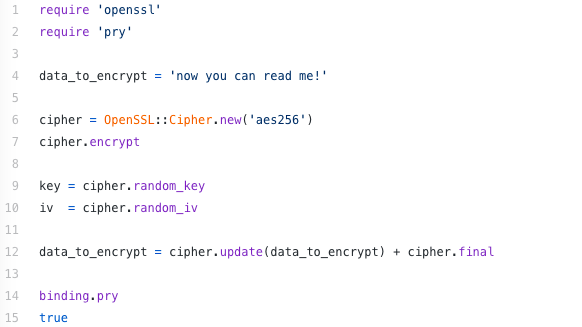
In this example, we reassign the variable which included the original string of raw data. This shows exactly how we are able to encrypt and decrypt data.
You can see how this data is encrypted by looking at in Pry console for Ruby:

In this example, you can see the data_to_encrypt variable, which was originally showing “now you can read me!” is an unintelligible string of gobbledegook. To decrypt, you would just reverse this process:
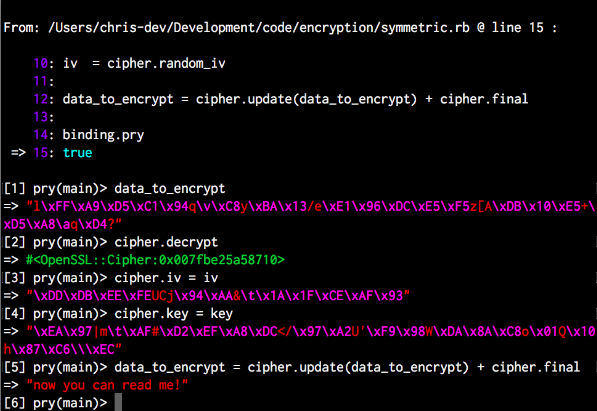
When you use the same key for encryption, you see the original message.
What is Asymmetric Encryption
What happens if you need to send data securely into an unknown environment, such as the internet? The same key that you use to encrypt and decrypt a message with would be necessary to send to open up a secure connection. This is an essential point of cryptography used in cryptocurrency.
This means that I must send the key over an insecure connection to get started, which means that the key may be intercepted along the way and used by a third party. To get around this, you would use asymmetric encryption.
Asymmetric encryption is also called a public key encryption. These algorithms use two keys that are mathematically similar, but they are used for different purposes. These are known as public or private keys. One is used for data encryption, and the other key decrypts the data. In this relationship, the private key is never revealed by the owner.
However, the public key can be spread to the public so that everyone has access. In addition, the private key is set up in a way that it can never be deduced simply from knowing the public key.
Asymmetric key algorithms are mostly used with mathematical problems such as integer factorization and discrete logarithmic problems. These can create digital signatures and establish session keys for cases like TLS protocol.
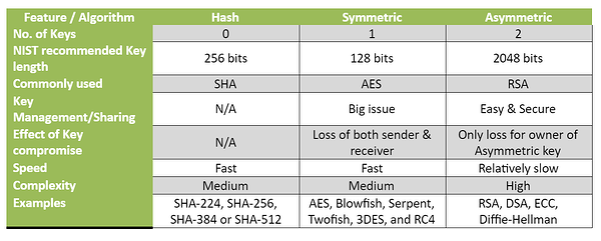
What is a Hash Function
Everything in modern cryptography is built from hash functions. They are the building blocks of all algorithms, and they can be used to transform random size data into a small fixed-size string. This data output is called the hash value or digest. The basic operation of hash functions works without needing any key to operate. It works simply in a one-way matter. This also makes it impossible to figure out the input from the output.
Hash functions are used for the following actions:
- Generate and verify digital signatures
- Checksum/message integrity assurance
- Source integrity services (via MAC)
- Derives sub-keys into key-establishment algorithms and protocols
- Generates pseudorandom numbers
Using Symmetric and Asymmetric Algorithms Together
Many in data security believe that the best algorithms take a double-headed approach by using a hybrid from asymmetric and symmetric algorithms. Ciphers for asymmetric algorithms are typically used for identity authentication, which is carried out through digital signatures and certifications. It can also be used for the distribution of symmetric encryption keys in bulk, as well as non-repudiation services and key agreement.
Further Reading: Specific Algorithms in Cryptography Mathematics
Big-O-Notation
Big-O-Notation – Indicated with the O(n) notation, which refers to O to the order of n, this notation is a way of indicating how many calculations are required to execute it.
Prime Factorization
Prime Factorization – This is a commonly used mathematical technique which uses the multiplication of two large prime numbers to secure encryption system that uses public keys.
Pseudo Random Number Generation
Pseudo-Random Number Generation – These are the algorithms used to generate random number sequences. However, unlike their hardware counterparts, they do not generate truly random numbers. They are used due to their speed.
The Birthday Problem
The Birthday Problem – This is a conceptualization of how probable it is that multiple people in a group have the same birthday. This concept is adopted to explain the probability of other phenomena.
RSA Algorithm
Of all the asymmetric algorithms, the RSA algorithm is the most widely known and used. It also serves as the foundational tools for Bio Cryptography. This takes the Biometric Template even further within the principles of cryptography. The RSA Algorithm started from the RSA Data Corporation, and its name was derived from Ron Rivest, Leonard Adelman, and Ali Shamir.
To understand the RSA Algorithm, you must first consider the power of prime numbers as these are central to this algorithm’s function. The RSA Algorithm uses prime numbers to generate public and private keys. However, the keys must be larger to accommodate copious amounts of data and information.
Instead, in this algorithm, the encryption is handled by symmetric algorithms for the private key, then goes through more encryption to generate a public key, which can then be used by the sending entity.
Once the public key is received, the private key, which has been created through the symmetric algorithm, is then decrypted. Now, the public key that was created originally by the RSA algorithm can be used to decrypt the rest of the message.
The Diffie-Hellman Algorithm
This algorithm is also known as the DH Algorithm. While DH is important for data security, it actually not used for encryption of the actual ciphertext. Instead, the main purpose for this algorithm is to seek out a solution for sending the public key and private key package through a secured channel.
Here is a step-by-step look at Diffie-Hellman algorithms:
- The receiving entity takes possession of the public key and private key, which was generated, but they have been automatically created by the DH algorithm
- The sending entity receives the public key generated by the receiving entity, thus using the Diffie-Hellman algorithm to create another section of public keys. However, these are only generated on a temporary basis
- The sending entity takes ownership of the new temporary private and public keys, which were sent by the receiving entity
- When the receiving entity finally gets the ciphertext message from the sending entity, the session key can reveal itself mathematically
- The receiving party can now decrypt the rest of the ciphertext message
Wrapping Up: The Mathematics of Cryptography
The algorithms created through cryptography are incredibly complex and unique. While they mostly handle the generation and usage of keys, the math is particularly important to specify how keys should behave between the sender and receiver. The algorithms also ensure that the ciphertext can’t be read unless the keys are used exactly as intended by the equation. This is the reason why two-factor authentication, digital signatures, and email messages require so much security.



